
License: Shareware $499
OS: Win2000,WinXP,Win7 x32,Win7 x64,Windows 8,Windows 10,WinServer,WinOther,WinVista
Requirements: c# vb .net html to pdf tutorial package requires .net framework 4.0 or .net core 2.0
Publisher: Jean Ashberg & The C# HTML to PDF Team
Homepage: https://ironpdf.com
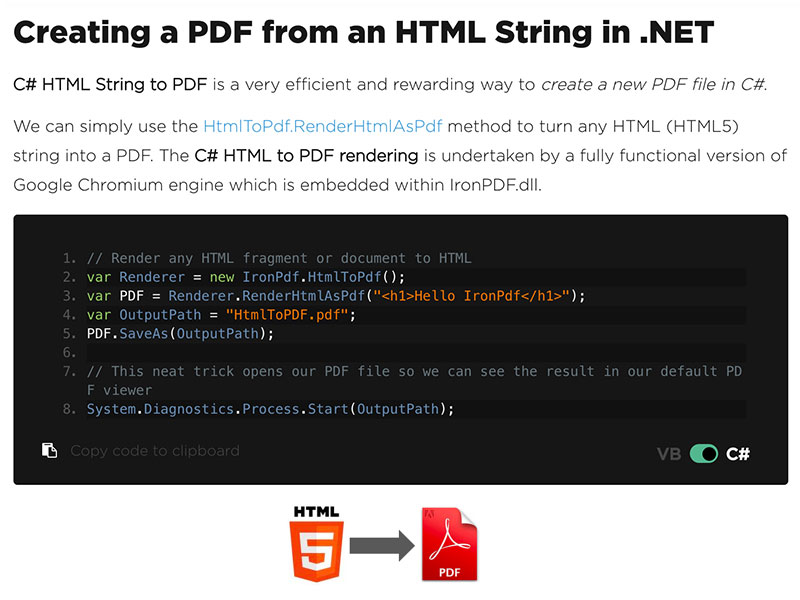
c# html to pdf – how to generate pdf files from html in c# .net applications and websites.
this developer software download contains a c# pdf generation and editing library in addition to a full tutorial on how it may be used. pdfs may actually be rendered from html with full css3 and javascript support with pixel-perfect embedded chromium rendering using the ironpdf c# pdf generator.
c# pdf library – the source code relies upon ironpdf which is a popular library for pdf development and editing for the microsoft .net framework https://www.nuget.org/packages/ironpdf/
c# html to pdf compatibility – this project is for use within any vb.net, c# or other il compatible .net language supporting microsoft .net framework version 4 or later to create:
– console applications
– asp.net web forms websites
– mvc web applications
– razor views
– windows forms desktop applications
– wpf layout applications
– server applications and windows servers
c# pdf tutorial package contents – the c# source-code contains .net examples and tutorials for:
– c# pdf library setup and installation
– html strings to pdf in c#
– generating pdfs from existing urls
– pdf file generation from html files including assets, css and javascript
– adding pdf file headers and footers (including c# and vb.net support for html headers and footers)
– html templating using .net strings and handlebars.net
– useful hints and tips such as responsive css & page-breaks in css and html5
for a detailed overview with code samples please visit https://ironpdf.com/tutorials/html-to-pdf/
going forwards developers may also learn to:
– encrypt and unlock pdf documents using 128 bit encryption
– edit pdf documents using html and c#
– add html headers, footers and watermarks to pdf files
– enhance pdfs with foreground and background images
– merged, joined, truncated and spliced pdf files as if they were arrays of pages using .net code
– extract text strings and images from any pdf file
